思考并回答以下问题:
- 选择排序算法是怎么样的?是两层循环吗?用js实现选择排序算法。
- 选择排序的步骤可分为两类:比较和交换,次数分别是什么样?
- 选择排序比冒泡排序快在哪里?
- 选择排序的效率如何?
- 为什么两种算法的大O记法完全一样,但实际上其中一个比另一个要快得多?
- 大O记法忽略常数是什么意思?
本章涵盖:
- 选择排序
- 选择排序实战
- 选择排序的实现
- 选择排序的效率
- 忽略常数
- 大O的作用
大O是一种能够比较算法效率,并告诉我们在特定环境下应采用何种算法的伟大工具。但我们不能完全依赖于它。因为有时候即使两种算法的大O记法完全一样,但实际上其中一个比另一个要快得多。
本章我们就来学习如何分辨那些效率貌似一样的算法,从而选出较快的那个。
选择排序
上一章分析了冒泡排序算法,其效率是O(N2)。现在我们再来探索另一种排序算法,选择排序,并将它跟冒泡排序对比一下。
选择排序的步骤如下:
(1)从左至右检查数组的每个格子,找出值最小的那个。在此过程中,我们会用一个变量来记住检查过的数字的最小值(事实上记住的是索引,但为了看起来方便,下图就直接写出数值)。如果一个格子中的数字比记录的最小值还要小,就把变量改成该格子的索引,如图所示。

(2)知道哪个格子的值最小之后,将该格与本次检查的起点交换。第1次检查的起点是索引0,第2次是索引1,以此类推。下图展示的是第一次检查后的交换动作。
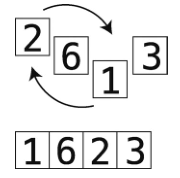
(3)重复第(1)(2)步,直至数组排好序。
选择排序实战
以数组[4,2,7,1,3]为例,步骤如下。
开始第1轮检查。
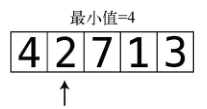
首先读取索引0。根据此算法的定义,它是目前遇到的最小值(因为现在只检查了一个格子),于是记下其索引。

第1步:将索引1的值2与目前的最小值4进行比较。
2比4还要小,于是将目前的最小值改为2。
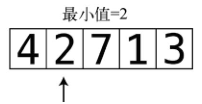
第2步:再与下一个值做比较。因为7大于2,所以最小值还是2。
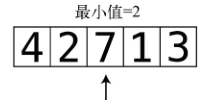
第3步:将1和目前的最小值做比较。
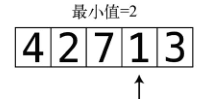
1比2还要小,于是目前的最小值更新为1。
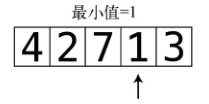
第4步:比较3和目前的最小值1。因为现在已经走到数组尽头了,所以可以断定1是整个数组的最小值。

第5步:本次检查的起点是索引0,不管那里的值是什么,我们都应该将最小值1换到那里。
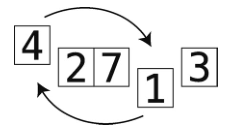
现在1就排到正确的位置上了。

可以开始第2轮检查了。
准备工作:因为索引0的值已符合其排位,所以这一轮从下一个格子开始,即索引1,其值为2,也是目前本轮所遇到的最小值。
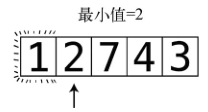
第6步:将7跟目前的最小值2进行比较。因为2小于7,所以最小值仍为2。
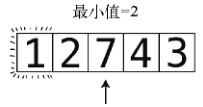
第7步:将4跟目前的最小值2进行比较。因为2小于4,所以最小值仍为2。
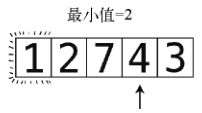
第8步:将3跟目前的最小值2进行比较。因为2小于3,所以最小值仍为2。

又走到数组尽头了。本轮不需要做任何交换,2已在其正确位置上。于是第2轮检查结束,现在数组如下图所示。

开始第3轮检查。
准备工作:从索引2起,其值为7。于是本轮目前最小值为7。
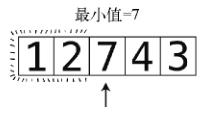
第9步:比较4与7。
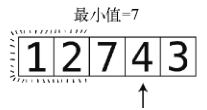
将4记为目前的最小值。
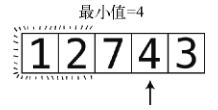
第10步:遇到3,它比4还小。
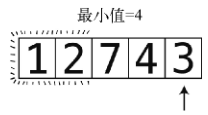
于是3成了目前的最小值。

第11步:到数组尽头了,将3跟本轮起点7进行交换。
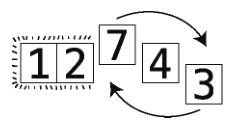
于是3排到正确位置上了。
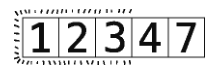
虽然我们可以看到现在整个数组都有序了,但计算机是看不到的,它只会继续第4轮检查。
准备工作:此轮检查从索引3开始,其值4是目前的最小值。
第12步:比较4和7。

4仍为最小值,而且它也处于本轮起点,因此无须任何交换。
因为最后一个格子左侧的那些值都已在各自的正确位置上,所以最后一格也必然正确,于是排序结束。

选择排序的实现
以下是用Javascript写的选择排序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24function selectionSort(array)
{
for(var i = 0; i < array.length; i++)
{
var lowestNumberIndex = i;
for(var j = i + 1; j < array.length; j++)
{
if(array[j] < array[lowestNumberIndex])
{
lowestNumberIndex = j;
}
}
if(lowestNumberIndex != i)
{
var temp = array[i];
array[i] = array[lowestNumberIndex];
array[lowestNumberIndex] = temp;
}
}
return array;
}
让我们来一行行地分析。我会先摘出代码片段,然后给出解释。1
for(var i = 0; i < array.length; i++) {}
这个外层的循环代表每一轮检查。在一轮检查之初,我们会先记住目前的最小值的索引。1
var lowestNumberIndex = i;
因此每轮开始时lowestNumberIndex都会是该轮的起点索引i。注意我们实际上记录的是最小值的索引,而非最小值本身。于是,第1轮开始时最小值的索引是0,到第2轮则是1,以此类推。1
for(var j = i + 1; j < array.length; j++) {}
此行代码发起一个以i + 1开始的内层循环。1
2
3
4if(array[j] < array[lowestNumberIndex])
{
lowestNumberIndex = j;
}
循环内逐个检查数组未排序的格子,若遇到比之前记录的本轮最小值还小的格子值,就将lowestNumberIndex更新为该格子的索引。
内层循环结束时,会得到未排序数值中最小值的索引。1
2
3
4
5
6if(lowestNumberIndex != i)
{
var temp = array[i];
array[i] = array[lowestNumberIndex];
array[lowestNumberIndex] = temp;
}
然后再看看这个最小值是否已在正确位置,即该索引是否等于i。如果不是,就将i所指的值与最小值交换。
选择排序的效率
选择排序的步骤可分为两类:比较和交换,也就是在每轮检查中把未排序的值跟该轮已遇到的最小值做比较,以及将最小值与该轮起点的值交换以使其位置正确。
在之前5个元素的例子里,我们总共进行了10次比较。每轮分别如下。
| 1 | 4 |
| 2 | 3 |
| 3 | 2 |
| 4 | 1 |
于是4 + 3 + 2 + 1 = 10次比较。
推广开来,若有N个元素,就会有(N - 1) + (N - 2) + (N - 3) + … + 1次比较。
但每轮的交换最多只有1次。如果该轮的最小值已在正确位置,就无须交换,否则要做1次交换。相比之下,冒泡排序在最坏情况(完全逆序)时,每次比较过后都要进行1次交换。
下表为冒泡排序和选择排序的并列对比。
| 5 | 20 | 14(10次比较 + 4次交换) |
| 10 | 90 | 54(45次比较 + 9次交换) |
| 20 | 380 | 199(180次比较 + 19次交换) |
| 40 | 1560 | 819(780次比较 + 39次交换) |
| 80 | 6320 | 3239(3160次比较 + 79次交换) |
从表中可以清晰地看到,选择排序的步数大概只有冒泡排序的一半,即选择排序比冒泡排序快一倍。
忽略常数
但有趣的是,选择排序的大O记法跟冒泡排序是一样的。
还记得我们说过,大O记法用来表示步数与数据量的关系。所以你可能会以为步数约为N2的一半的选择排序,其大O会写成O(N2/2),以表示N个元素需要N2/2步。如下表所示。
| 5 | 52 / 2 = 12.5 | 14 |
| 10 | 102 / 2 = 50 | 54 |
| 20 | 202 / 2 = 200 | 199 |
| 40 | 402 / 2 = 800 | 819 |
| 80 | 802 / 2 = 3200 | 3239 |
但事实上,选择排序的大O记法为O(N2),跟冒泡排序一样。这是因为大O记法的一条重要规则我们至今还没提到:
大O记法忽略常数。
换一种不那么数学的表达方式,就是:大O记法不包含一般数字,除非是指数。
如刚才的例子,严格来说本应为O(N2/2),最终得写成O(N2)。类似地,O(2N)要写成O(N);O(N/2)也写成O(N);就算是比O(N)慢100倍的O(100N),也要写成O(N)。
速度相差100倍的两种算法,它们的大O记法却一样,这或许会让人觉得大O没什么意义。就像同为O(N)的选择排序和冒泡排序,其实前者比后者快1倍,要在二者之中挑选,无疑是用选择排序。
那么,大O还凭什么值得我们学习呢?
大O的作用
尽管不能比较冒泡排序和选择排序,大O还是很重要的,因为它能够区分不同算法的长期增长率。当数据量达到一定程度时,O(N)的算法就会永远快过O(N2),无论这个O(N)实际上是O(2N)还是O(100N)。即使是O(100N),这个临界点也是存在的。(第3章在比较一个100步的算法与O(N)算法时,也提过这个概念,不过这次我们会用另一个例子来讲解。)
下图为O(N)和O(N2)的对比。
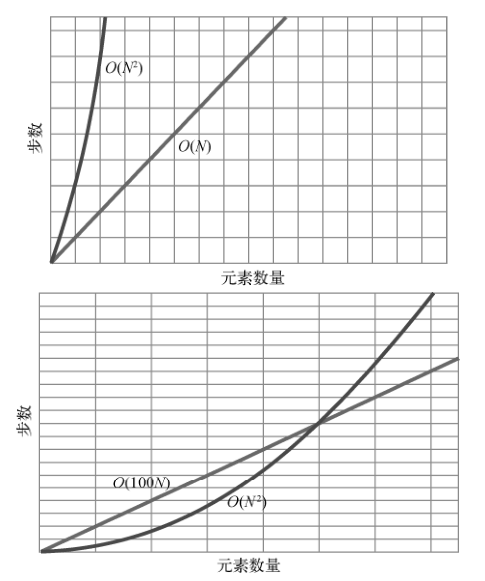
此图在上一章里出现过。它显示了不管数据量是多少,O(N)总是快过O(N2)。
在第二幅图中,我们看到当数据量少于某个值时,O(N2)是比O(100N)要快的,但过了这个值之后,O(100N)便反超O(N2),并一直保持优势。
这就是大O记法忽略常数的原因。大O记法只表明,对于不同分类,存在一临界点,在这一点之后,一类算法会快于另一类,并永远保持下去。至于这个点在哪里,大O并不关心。
因此,不需要写成O(100N),归类到O(N)就好了。
同样地,在数据量增大到某个点时,O(log N)便会永远超越O(N),即使该O(log N)算法的实际步数为O(2log N)。
所以大O是极为有用的工具,当两种算法落在不同的大O类别时,你就很自然地知道应该选择哪种。因为在大数据的情况下,必然存在一临界点使这两种算法的速度永远区分开来。
不过,本章的主要结论是即使两种算法的大O记法一样,但实际速度也可能并不一样。虽然选择排序比冒泡排序快1倍,但它们的大O记法都是O(N2)。因此,大O记法非常适合用于不同大O分类下的算法的对比,对于大O同类的算法,我们还需要进一步的解析才能分辨出具体差异。
一个实例
假设你要写一个Ruby程序,从一个数组里取出间隔的元素,来组成新的数组。你可能会用数组的each_with_index方法来做如下遍历。
1 | def every_other(array) |
它迭代原数组的每一个元素,如果元素索引值为偶数,则将该元素插入到新数组里。
分析其中步骤,会发现它们可分为两种:一种是读取数组元素,另一种是插入元素到新数组。
因为要读取数组的每一个元素,所以读取有N步。插入则只有N/2步,因为只有间隔的元素才被放到新数组里。从技术上来说,N次读取加N/2次插入,这算法的效率应该是O(N+(N/2)),或者是O(1.5N)。但因为大O记法要把常数丢掉,所以只写成O(N)。
此算法虽然能达到效果,但我们还是要再审视一下它有没有提升的空间。事实上,有。
与其迭代每个元素并检查它们的索引是否为偶数,不如只读取数组中间隔的元素。1
2
3
4
5
6
7
8
9def every_other(array)
new_array = []
index = 0
while index < array.length
new_array << array[index]
index += 2
end
return new_array
end
这种做法的while循环会跳过间隔的元素,因此避免了检查每个元素。结果就是有N个元素,会有N/2次读取,N/2次插入。它跟第一种做法一样,记为O(N)。
然而,第一种做法实际有1.5N步,比只有N步的第二种明显要慢。虽然第一种的写法在Ruby界更为惯用,但如果要处理的数据量庞大,不妨尝试第二种,以获得性能的飞升。
总结
现在我们已经掌握了一些非常强大的算法分析手法。我们能够使用大O去判断各种算法的效率,即便两种算法的大O记法一样,也知道如何对比它们。
不过在对比算法时,还需要考虑一个重要因素。至今我们关注的都是最坏情况下算法会跑得多慢,但其实最坏情况并不总会发生。没错,我们遇到的大都是平均情况。下一章,我们会学习怎样顾及所有情况。