思考并回答以下问题:
- 为什么栈和队列都是处理临时数据的灵活工具?
- 栈的数据结构是什么样的?应用场景有哪些?
- 队列的数据结构是什么样的?应用场景有哪些?
本章涵盖:
- 栈
- 栈实战
- 队列
- 队列实战
迄今为止,我们对数据结构的讨论都集中于它们在各种操作上表现出的性能。但其实,掌握多种数据结构还有助于简化代码,提高可读性。
本章你将会学习两种新的数据结构:栈和队列。事实上它们并不是全新的东西,只不过是多加了一些约束条件的数组而已。但正是这些约束条件为它们赋予了巧妙的用法。
具体一点说,栈和队列都是处理临时数据的灵活工具。在操作系统、打印任务、数据遍历等各种需要临时容器才能构造出美妙算法的场景,它们都大有作为。
处理临时数据就像是点餐。在菜做好并送到客人手上之前,订单是有用的,但过后,你无须保留那张订单。临时数据就是一些处理完便不再有用的信息,因此没有保留的必要。此外,就像出菜时应先出给早下单的客人,你可能还得注意数据按什么顺序去处理。栈和队列就正好能把数据按顺序处理,并在处理完成后将其抛弃。
栈
栈存储数据的方式跟数组一样,都是将元素排成一行。只不过它还有以下 3条约束。
- 只能在末尾插入数据。
- 只能读取末尾的数据。
- 只能移除末尾的数据。
你可以将栈看成一叠碟子:你只能看到最顶端那只碟子的碟面,其他都看不到。另外,要加碟子只能往上加,不能往中间塞,要拿碟子只能从上面拿,不能从中间拿(至少你不应该这么做)。绝大部分计算机科学家都把栈的末尾称为栈顶,把栈的开头称为栈底。
尽管这些约束看上去令人很拘束,但很快你就会发现它们带来的好处。
我们先从一个空栈开始演示。
往栈里插入数据,也叫作压栈。你可以想象把一个碟子压在其他碟子上的画面。
首先,将5压入栈中。
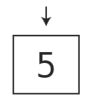
这没什么特别的,就如往数组插入数据一样平常。
接着,将3压入栈中。
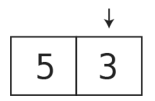
再将0压入栈中。
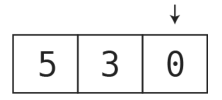
注意,每次压栈都是把数据加到栈顶(也就是栈的末尾)。如果想把0插入到栈底或中间,那是不允许的,因为这就是栈的特性:只能在末尾插入数据。
从栈顶移除数据叫作出栈。这也是栈的限制:只能移除末尾的数据。
来把栈中的一些数据弹出。
首先,弹出0。
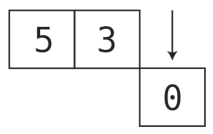
现在剩下两个元素,5和3。
接着,弹出3。
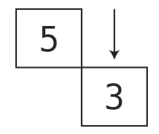
这就剩下5了。
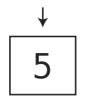
压栈和出栈可被形容为LIFO(last in,first out)后进先出。解释起来就是最后入栈的元素,会最先出栈。就像无心向学的学生,最迟到校的总是他,最早回家的也是他。
栈实战
栈很少用于需要长期保留数据的场景,却常用于各种处理临时数据的算法。
下面我们来写一个初级的JavaScript分析器--一种用来检查JavaScript代码的语法是否正确的工具。因为JavaScript的语法规则很多,所以它可以做得很复杂。简单起见,我们就只专注于检查括号的闭合情况吧,包括圆括号、方括号、花括号,这些地方搞错的话是很令人郁闷的。
在写之前,先分析一下括号的语法错误会有哪些情况。分类就是以下3种。
首先是有左括号没有右括号的情况。1
(var x = 2;
这种归为第1类。
接着是没有左括号但有右括号的情况。1
var x = 2;)
这种归为第2类。
还有第3类,右括号类型与其前面最近的左括号不匹配,例如:1
(var x = [1, 2, 3)];
此例中,虽然圆括号和方括号都左右成对出现,但位置不对,右圆括号前面最近的竟是左方括号。
那么怎样才能实现一种能检查一行代码里括号写得对不对的算法呢?用栈就好办了。
先准备一个空栈,然后从左至右读取代码的每一个字符,并执行以下规则。
(1) 如果读到的字符不是任一种括号(圆括号、方括号、花括号),就忽略它,继续下一个。
(2) 如果读到左括号,就将其压入栈中,意味着后面需要有对应的右括号来做闭合。
(3) 如果读到右括号,就查看栈顶的元素,并做如下分析。
- 如果栈里没有任何元素,也就是遇到了右括号但没有左括号,即第2类语法错误。
- 如果栈里有数据,但与刚才读到的右括号类型不匹配,那就是第3类语法错误。
- 如果栈顶元素是匹配的左括号,则表示它已经闭合。那么就可以将其弹出,因为已经不需要再记住它了。
(4) 如果一行代码读完,栈里还留有数据,那就表示存在左括号,没有右括号与之匹配,即第1类语法错误。
让我们用以下代码作为例子来演示一遍。
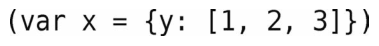
备好一个空栈之后,就可以开始从左至右读取代码的每个字符了。
第1步:首先是第一个字符,它是一个左圆括号。
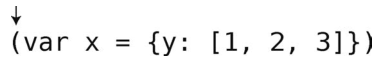
第2步:因为它是一个左括号,所以将其压入栈中。
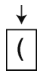
接下来的var x = ,没有一个是括号,因此会被忽略。
第3步:遇到一个左花括号。
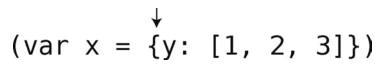
第4步:将其压入栈中。
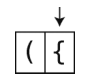
然后忽略y:。
第5步:遇到一个左方括号。
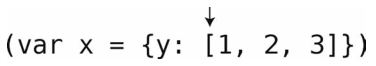
第6步:同样把它压入栈中。
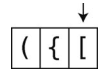
然后忽略1, 2, 3 。
第7步:这时我们第一次看到了右括号,是一个右方括号。
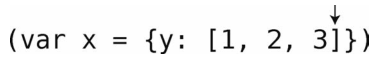
第8步:于是检查栈顶的元素,发现那是一个左方括号。因为刚才读到的右方括号能与其配对,所以将左方括号弹出。
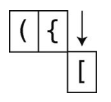
第9步:继续,下一个读到的是右花括号。
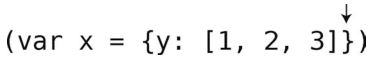
第10步:检查栈里的最后一个元素,刚好是可以配对的左花括号。于是将其弹出。
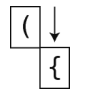
第11步:读到一个右圆括号。
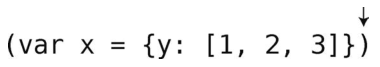
第12步:检查栈里的最后一个元素,刚好是可以配对的左圆括号。于是将其弹出,剩下一个空栈。
至此,代码读完了,栈也空着,所以我们的分析器可以定论,这段代码在括号方面没有语法错误。
以下是上述算法的Ruby实现。Ruby的数组自带push和pop方法,是在数组结尾插入和删除元素的便捷调用。只使用这两个方法的话,数组便形同于栈。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class Linter
attr_reader :error
def initialize
# 用一个普通的数组来当作栈
@stack = []
end
def lint(text)
# 循环读取文本的每个字符
text.each_char.with_index do |char, index|
if opening_brace?(char)
# 如果读到左括号,则将其压入栈中
@stack.push(char)
elsif closing_brace?(char)
if closes_most_recent_opening_brace?(char)
# 如果读到右括号,并且它与栈顶的左括号匹配,
# 则将栈顶弹出
@stack.pop
else # 如果读到右括号,但它与栈顶的左括号不匹配
@error = "Incorrect closing brace: #{char} at index #{index}"
return
end
end
end
if @stack.any?
# 如果读完所有字符后栈不为空,就表示文中存在着没有相应右括号的左括号
@error = "#{@stack.last} does not have a closing brace"
end
end
private
def opening_brace?(char)
["(", "[", "{"].include?(char)
end
def closing_brace?(char)
[")", "]", "}"].include?(char)
end
def opening_brace_of(char)
{")" => "(", "]" => "[", "}" => "{"}[char]
end
def most_recent_opening_brace
@stack.last
end
def closes_most_recent_opening_brace?(char)
opening_brace_of(char) == most_recent_opening_brace
end
end
如果这样使用的话:1
2
3linter = Linter.new
linter.lint("( var x = { y: [1, 2, 3] } )")
puts linter.error
因为该段代码语法正确,所以不会有错误信息打印出来。然而,要是不小心调转了最后两个字符:1
2
3linter = Linter.new
linter.lint("( var x = { y: [1, 2, 3] ) }")
puts linter.error
就会出现以下信息。1
Incorrect closing brace: ) at index 25
如果丢掉最后那个右括号:1
2
3linter = Linter.new
linter.lint("( var x = { y: [1, 2, 3] }")
puts linter.error
就会出现如下的报错。1
( does not have a closing brace
在刚才的例子中,栈被巧妙地用来跟踪那些还没有配对的左括号。到了下一章,我们会类似地用栈去跟踪函数的调用,那也是递归的核心思想。
当数据的处理顺序要与接收顺序相反时(LIFO),用栈就对了。像文字处理器的“撤销”动作,或网络应用程序的函数调用,你应该都会需要栈来实现。
队列
队列对于临时数据的处理也十分有趣,它跟栈一样都是有约束条件的数组。区别在于我们想要按什么顺序去处理数据,而这个顺序当然是要取决于具体的应用场景。
你可以将队列想象成是电影院排队。排在最前面的人会最先离队进入影院。套用到队列上,就是首先加入队列的,将会首先从队列移出。因此计算机科学家都用缩写“FIFO”(first in, first out)先进先出,来形容它。
与栈类似,队列也有3个限制(但内容不同)。
- 只能在末尾插入数据(这跟栈一样)。
- 只能读取开头的数据(这跟栈相反)。
- 只能移除开头的数据(这也跟栈相反)。
下面来看看它是怎么运作的,先准备一个空队列。
首先,插入5(虽然栈的插入就叫压栈,但队列的插入却没有固定的叫法,一般可以叫放入、加入、入队)。
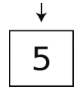
然后,插入9。
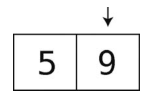
接着,插入100。
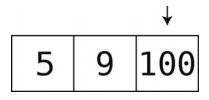
目前为止,队列表现得还跟栈一样,但要是移除数据的话,就会跟栈反着来了,因为队列是从开头移除数据的。
想移除数据,得先从5开始,因为开头就是它。
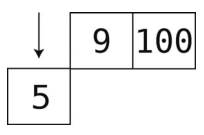
接着,移除9。
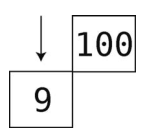
这样一来,队列就只剩下100了。
队列实战
队列应用广泛,从打印机的作业设置,到网络应用程序的后台任务,都有队列的存在。
假设你正在用Ruby编写一个简单的打印机接口,以接收网络上不同计算机的打印任务。利用Ruby数组的push 方法,将数据加到数组末尾,以及 shift方法,将数据从数组开头移除。
你可以这样来编写接口类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class PrintManager
def initialize
@queue = []
end
def queue_print_job(document)
@queue.push(document)
end
def run
while @queue.any?
# Ruby 的 shift 方法可移出并返回数组的第一个元素
print(@queue.shift)
end
end
private def print(document)
# 让打印机去打印文档(为了演示,暂时先打到终端上)
puts document
end
end
然后这样使用它。1
2
3
4
5print_manager = PrintManager.new
print_manager.queue_print_job("First Document")
print_manager.queue_print_job("Second Document")
print_manager.queue_print_job("Third Document")
print_manager.run
接着打印机就会按3份文档的接收顺序来把它们打印出来。1
2
3First Document
Second Document
Third Document
尽管这个例子把打印机的工作方式写得很抽象,简化了细节,但其中对队列基本用法的描述是真实的,以此为基础去构建真正的打印系统是可行的。
队列也是处理异步请求的理想工具--它能保证请求按接收的顺序来执行。此外,它也常用于模拟现实世界中需要有序处理事情的场景,例如飞机排队起飞、病人排队看医生。
总结
如你所见,栈和队列是能巧妙解决各种现实问题的编程工具。
掌握了栈和队列,就解锁出了下一个目标:学习基于栈的递归。递归也是其他高级算法的基础,我们将会在本书余下的部分讲解它们。
数组与数据结构
在强类型编程语言中,有专用的数据结构解决方案。通常是创建一个容器,在这个容器中可以存储任意类型的数据,并且可以根据容器中存储的数据决定容器的容量,达到可以变长的容器结构,比如链表、堆栈和队列等都是数据结构中常用的形式。在PHP中,通常都是使用数组来完成其它语言使用数据结构才能完成的工作。它是弱类型语言,在同一个数组中就可以存储多种类型的数据,而且php中的数组没有长度限制,数组存储数据的容量还可以根据里面元素个数的增减自动调整。
1、使用数组实现堆栈
堆栈是数据结构的一种实现形式,数据存储时采用“先进后出”的数据结构。在php中,将数组当作一个栈使用array_push()和array_pop()两个函数即可完成数据的进栈和出栈操作。1
2-->array_push():将一个或多个单元压入数组末尾(入栈),然后返回新组的长度。
-->array_pop():将数组最有一个单元弹出数组(出栈)
2、使用数组实现队列
队列是数据结构的一种实现形式,数据存储时采用“先进先出”的数据结构。在php中,将数组当作一个栈使用array_push()和array_shift()两个函数即可完成数据的队列操作。1
2-->array_shift():将数组开头的单元移出数组,然后返回被删元素值。
-->array_shift():在数组开头插入一个或多个单元