思考并回答以下问题:
- 什么是树的层次?什么是有序树和无序树?
- 结点的度和树的度有什么区别?树的度 = max([结点的度,…,…])怎么理解?
- 树的度和树的深度有什么区别?
- 满二叉树和完全二叉树有什么区别?
线性结构中的数据元素是一对一的关系。树形结构是一对多的非线性结构,非常类似于自然界中的树,数据元素之间既有分支关系,又有层次关系。在数据库系统中,树形结构是数据的重要组织形式之一。树形结构有树和二叉树两种,树的操作实现比较复杂,但树可以转换为二叉树进行处理,所以,本章主要讨论二叉树。
树
树的定义
树(Tree)是 n(n≥0)个相同类型的数据元素的有限集合。树中的数据元素叫结点(Node)。n = 0的树称为空树(Empty Tree);对于n>0 的任意非空树T有:
- (1)有且仅有一个特殊的结点称为树的根(Root)结点,根没有前驱结点;
- (2)若n>1,则除根结点外,其余结点被分成了m(m>0)个互不相交的集合T1,T2,…,Tm,其中每一个集合Ti(1≤i≤m)本身又是一棵树。树T1,T2,…,Tm称为这棵树的子树(Subtree)。
由树的定义可知,树的定义是递归的,用树来定义树。因此,树(以及二叉树)的许多算法都使用了递归。
树的形式定义为:树(Tree)简记为 T,是一个二元组,
其中:
- D是结点的有限集合;
- R是结点之间关系的有限集合。
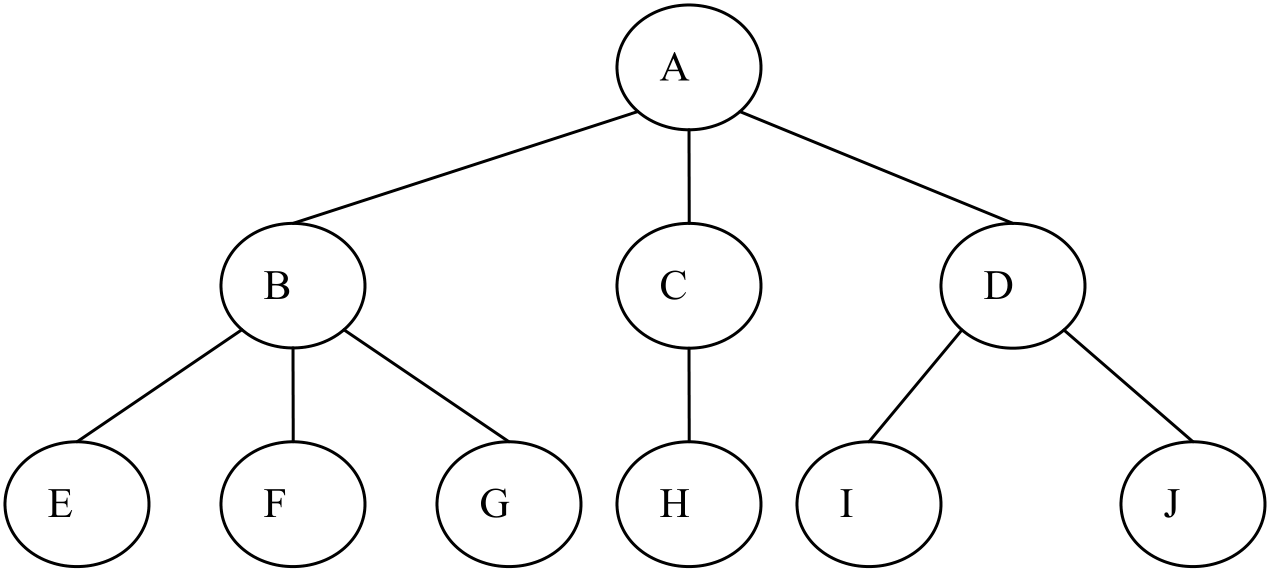
图1是一棵具有10个结点的树,即T={A, B, C, D, E, F, G, H, I, J}。结点A是树T的根结点,根结点A没有前驱结点。除A之外的其余结点分成了三个互不相交的集合:T1={B, E, F, G},T2={C, H},T3={D, I, J},分别形成了三棵子树,B、C和D分别成为这三棵子树的根结点,因为这三个结点分别在这三棵子树中没有前驱结点。
图1 树的示意图
从树的定义和图1的示例可以看出,树具有下面两个特点:
- (1)树的根结点没有前驱结点,除根结点之外的所有结点有且只有一个前驱结点。
- (2)树中的所有结点都可以有零个或多个后继结点。
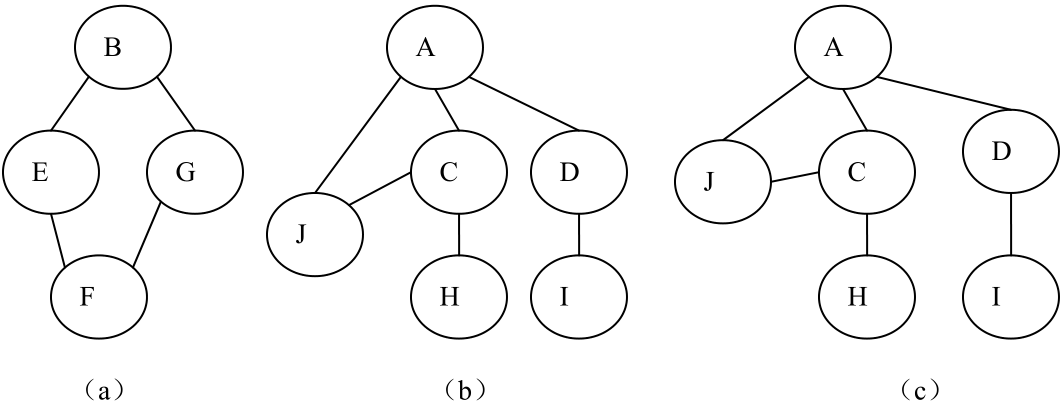
实际上,第(1)个特点表示的就是树形结构的“一对多关系”中的“一”,第(2)个特点表示的是“多”。由此特点可知,图2所示的都不是树。
图2 非树结构示意图
树的相关术语
树的相关术语有以下一些:
- 1、结点(Node):表示树中的数据元素,由数据项和数据元素之间的关系组成。在图1中,共有10个结点。
- 2、结点的度(Degree of Node):结点所拥有的子树的个数,在图1中,结点A的度为3。
- 3、树的度(Degree of Tree):树中各结点度的最大值。在图1中,树的度为3。
- 4、叶子结点(Leaf Node):度为0的结点,也叫终端结点。在图1中,结点E、F、G、H、I、J都是叶子结点。
- 5、分支结点(Branch Node):度不为0的结点,也叫非终端结点或内部结点。在图1中,结点 A、B、C、D 是分支结点。
- 6、孩子(Child):结点子树的根。在图1中,结点B、C、D是结点A的孩子。
- 7、双亲(Parent):结点的上层结点叫该结点的双亲。在图1中,结点 B、C、D的双亲是结点 A。
- 8、祖先(Ancestor):从根到该结点所经分支上的所有结点。在图1中,结点E的祖先是A和B。
- 9、子孙(Descendant):以某结点为根的子树中的任一结点。在图1中,除A之外的所有结点都是A的子孙。
- 10、兄弟(Brother):同一双亲的孩子。在图1中,结点B、C、D 互为兄弟。
- 11、结点的层次(Level of Node):从根结点到树中某结点所经路径上的分支数称为该结点的层次。根结点的层次规定为1,其余结点的层次等于其双亲结点的层次加1。
- 12、堂兄弟(Sibling):同一层的双亲不同的结点。在图1中,G和H互为堂兄弟。
- 13、树的深度(Depth of Tree):树中结点的最大层次数。在图1中,树的深度为3。
- 14、无序树(Unordered Tree):树中任意一个结点的各孩子结点之间的次序构成无关紧要的树。通常树指无序树。
- 15、有序树(Ordered Tree):树中任意一个结点的各孩子结点有严格排列次序的树。二叉树是有序树,因为二叉树中每个孩子结点都确切定义为是该结点的左孩子结点还是右孩子结点。
- 16、森林(Forest):m(m≥0)棵树的集合。自然界中的树和森林的概念差别很大,但在数据结构中树和森林的概念差别很小。从定义可知,一棵树有根结点和m个子树构成,若把树的根结点删除,则树变成了包含m棵树的森林。当然,根据定义,一棵树也可以称为森林。
树的基本操作
树的操作很多,比如访问根结点,得到结点的值、求结点的双亲结点、某个子结点和某个兄弟结点。又比如,插入一个结点作为某个结点的最左子结点、最右子结点等。删除结点也是一样。也可按照某种顺序遍历一棵树。在这些操作中,有些操作是针对结点的(访问父亲结点、兄弟结点或子结点),有些操作是针对整棵树的(访问根结点、遍历树)。如果像前面几种数据结构用接口表示树的操作的话,就必须把结点类的定义写出来。但本章的重点不是树而是二叉树。所以,树的操作不用接口来表示,只给出操作的名称和功能。
树的基本操作通常有以下10种:
- 1、Root():求树的根结点,如果树非空,返回根结点,否则返回空;
- 2、Parent(t):求结点t的双亲结点。如果t的双亲结点存在,返回双亲结点,否则返回空;
- 3、Child(t,i):求结点 t 的第 i 个子结点。如果存在,返回第 i 个子结点,否则返回空;
- 4、RightSibling(t):求结点t第一个右边兄弟结点。如果存在,返回第一个右边兄弟结点,否则返回空;
- 5、Insert(s,t,i):把树s插入到树中作为结点t的第i棵子树。成功返回true,否则返回 false;
- 6、Delete(t,i):删除结点t的第i棵子树。成功返回第i棵子树的根结点,否则返回空;
- 7、Traverse(TraverseType):按某种方式遍历树;
- 8、Clear():清空树;
- 9、IsEmpty():判断树是否为空树。如果是空树,返回true,否则返回 false;
- 10、GetDepth():求树的深度。如果树不为空,返回树的层次,否则返回0。
二叉树
二叉树的定义
二叉树(Binary Tree)是n(n≥0)个相同类型的结点的有限集合。n=0的二叉树称为空二叉树(Empty Binary Tree);对于n>0的任意非空二叉树有:
- (1)有且仅有一个特殊的结点称为二叉树的根(Root)结点,根没有前驱结点;
- (2)若n>1,则除根结点外,其余结点被分成了2个互不相交的集合TL,TR,而TL、TR本身又是一棵二叉树,分别称为这棵二叉树的左子树(Left Subtree)和右子树(Right Subtree)。
二叉树的形式定义为:二叉树(Binary Tree)简记为BT,是一个二元组,
其中:
- D是结点的有限集合;
- R是结点之间关系的有限集合。
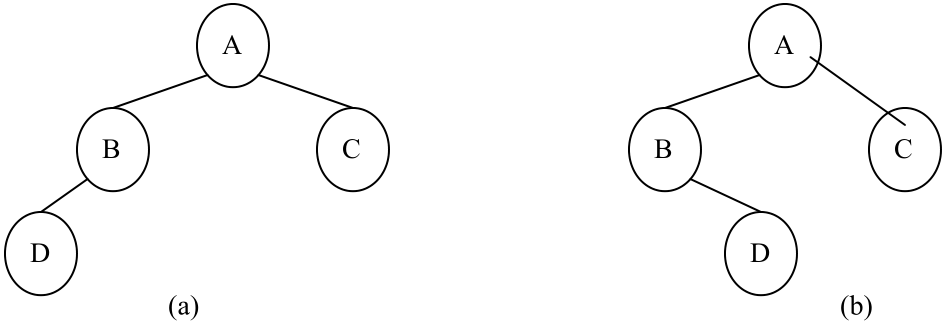
由树的定义可知,二叉树是另外一种树形结构,并且是有序树,它的左子树和右子树有严格的次序,若将其左、右子树颠倒,就成为另外一棵不同的二叉树。因此,图5(a)和图5(b)所示是不同的二叉树。
图5 两棵不同的二叉树
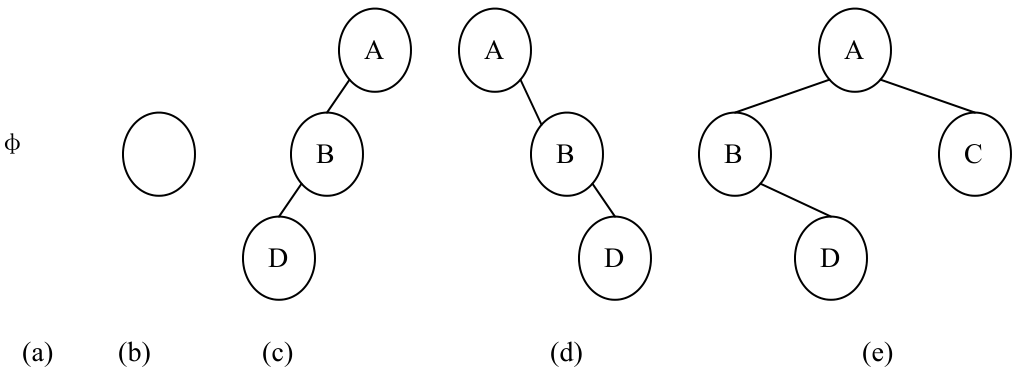
二叉树的形态共有5种:空二叉树、只有根结点的二叉树、右子树为空的二叉树、左子树为空的二叉树和左、右子树非空的二叉树。二叉树的5种形态如图6所示。
图6 二叉树的5种形态
下面介绍两种特殊的二叉树。
图7 满二叉树与完全二叉树
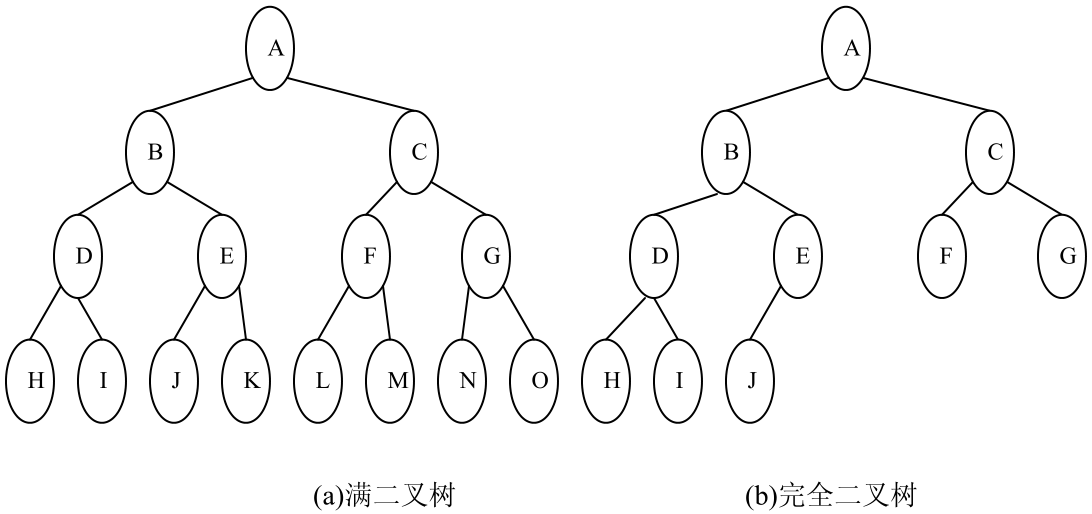
(1)满二叉树(Full Binary Tree):如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树,如图7(a)所示。
由定义可知,对于深度为k的满二叉树的结点个数为2k -1。
(2)完全二叉树(Complete Binary Tree):深度为k,有n个结点的二叉树当且仅当其每一个结点都与深度为k,有n个结点的满二叉树中编号从1到n的结点一一对应时,称为完全二叉树,如图7(b)所示。
完全二叉树的特点是叶子结点只可能出现在层次最大的两层上,并且某个结点的左分支下子孙的最大层次与右分支下子孙的最大层次相等或大1。
满二叉树和完全二叉树的区别
1、定义不同
完全二叉树指除最后一层外,每一层上的节点数都达到最大值;在最后一层上只缺少右边的若干节点。
满二叉树指每一个层的结点数都达到最大值,即除最后一层外,每一层上的所有节点都有两个子节点。
2、关系不同
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树。
二叉树的性质
性质1 一棵非空二叉树的第i层上最多有2i-1个结点(i≥1)。
证明:采用数学归纳法进行证明。当n=1时,二叉树只有1层,这一层只有根结点一个结点,所以第1层的结点数为21-1=1,结论成立。假设当n=N时结论成立,即第N层最多有2N-1个结点;当n=N+1时,根据二叉树的定义,第N层的每个结点最多有2个子结点,所以第N+1层上最多有2N-1*2=2N=2(N+1)-1个结点,结论成立。综上所述,性质1成立。
性质2 若规定空树的深度为0,则深度为k的二叉树最多有2k -1 个结点(k≥0)。
证明:当k=0 时,空树的结点数为 2 0 -1=0,结论成立。当深度为k(k>0)时,由性质 1 可知,第i(1≤i≤k)层最多有 2 i-1 个结点,所以二叉树的最多结点数是:
二叉链表存储结构的类实现
二叉树的二叉链表的结点类有3个成员字段:数据域字段data、左孩子引用域字段lChild和右孩子引用域字段rChild。二叉树的二叉链表的结点类的实现如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77public class Node<T>
{
private T data; // 数据域
private Node<T> lChild; // 左孩子
private Node<T> rChild; // 右孩子
// 构造器
public Node(T val, Node<T> lp, Node<T> rp)
{
data = val;
lChild = lp;
lChild = rp;
}
// 构造器
public Node(Node<T> lp, Node<T> rp)
{
data = default(T);
lChild = lp;
rChild = rp;
}
// 构造器
public Node(T val)
{
data = val;
lChild = null;
rChild = null;
}
// 构造器
public Node()
{
data = default(T);
lChild = null;
rChild = null;
}
// 数据属性
public T Data
{
get
{
return data;
}
set
{
value = data;
}
}
// 左孩子属性
public Node<T> LChild
{
get
{
return lChild;
}
set
{
lChild = value;
}
}
// 右孩子属性
public Node<T> RChild
{
get
{
return rChild;
}
set
{
rChild = value;
}
}
}
不带头结点的二叉树的二叉链表比带头结点的二叉树的二叉链表的区别与不带头结点的单链表与带头结点的单链表的区别一样。下面只介绍不带头结点的二叉树的二叉链表的类BiTree<T>。BiTree<T>类只有一个成员字段head表示头引用。以下是BiTree<T>类的实现。
1 | public class BiTree<T> |
二叉树的遍历
二叉树的遍历是指按照某种顺序访问二叉树中的每个结点,使每个结点被访问一次且仅一次。遍历是二叉树中经常要进行的一种操作,因为在实际应用中,常常要求对二叉树中某个或某些特定的结点进行处理,这需要先查找到这个或这些结点。
实际上,遍历是将二叉树中的结点信息由非线性排列变为某种意义上的线性排列。也就是说,遍历操作使非线性结构线性化。
由二叉树的定义可知,一棵二叉树由根结点、左子树和右子树三部分组成,若规定D、L、R分别代表遍历根结点、遍历左子树、遍历右子树,则二叉树的遍历方式有6种:DLR、DRL、LDR、LRD、RDL、RLD。由于先遍历左子树和先遍历右子树在算法设计上没有本质区别,所以,只讨论三种方式:DLR(先序遍历)、LDR(中序遍历)和LRD(后序遍历)。
除了这三种遍历方式外,还有一种方式:层序遍历(Level Order)。层序遍历是从根结点开始,按照从上到下、从左到右的顺序依次访问每个结点一次仅一次。
由于树的定义是递归的,所以遍历算法也采用递归实现。下面分别介绍这四种算法,并把它们作为BiTree<T>类成员方法。
1、先序遍历(DLR)
先序遍历的基本思想是:首先访问根结点,然后先序遍历其左子树,最后先序遍历其右子树。先序遍历的递归算法实现如下,注意:这里的访问根结点是把根结点的值输出到控制台上。当然,也可以对根结点作其它处理。
1 | public void PreOrder(Node<T> root) |
对于图7(b)所示的二叉树,按先序遍历所得到的结点序列为:1
A B D H I E J C F G
2、中序遍历(LDR)
中序遍历的基本思想是:首先中序遍历根结点的左子树,然后访问根结点,最后中序遍历其右子树。中序遍历的递归算法实现如下:
1 | public void InOrder(Node<T> root) |
对于图7(b)所示的二叉树,按中序遍历所得到的结点序列为:1
H D I B J E A F C G
3、后序遍历(LRD)
后序遍历的基本思想是:首先后序遍历根结点的左子树,然后后序遍历根结点的右子树,最后访问根结点。后序遍历的递归算法实现如下:
1 | public void PostOrder(Node<T> root) |
对于图7(b)所示的二叉树,按后序遍历所得到的结点序列为:1
H I D J E B F G C A
4、层序遍历(Level Order)
层序遍历的基本思想是:由于层序遍历结点的顺序是先遇到的结点先访问,与队列操作的顺序相同。所以,在进行层序遍历时,设置一个队列,将根结点引用入队,当队列非空时,循环执行以下三步:
- (1)从队列中取出一个结点引用,并访问该结点;
- (2)若该结点的左子树非空,将该结点的左子树引用入队;
- (3)若该结点的右子树非空,将该结点的右子树引用入队;
层序遍历的算法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public void LevelOrder(Node<T> root)
{
//根结点为空
if (root == null)
{
return;
}
//设置一个队列保存层序遍历的结点
CSeqQueue<Node<T>> sq = new CSeqQueue<Node<T>>(50);
//根结点入队
sq.In(root);
//队列非空,结点没有处理完
while (!sq.IsEmpty())
{
//结点出队
Node<T> tmp = sq.Out();
//处理当前结点
Console.WriteLine("{o}", tmp);
//将当前结点的左孩子结点入队
if (tmp.LChild != null)
{
sq.In(tmp.LChild);
}
//将当前结点的右孩子结点入队
if (tmp.RChild != null)
{
sq.In(tmp.RChild);
}
}
}
对于图7(b)所示的二叉树,按层次遍历所得到的结点序列为:1
A B C D E F G H I J
应用举例
【例1】编写算法,在二叉树中查找值为value的结点。
算法思路:在二叉树中查找具有某个特定值的结点就是遍历二叉树,对于遍历到的结点,判断其值是否等于value,如果是则返回该结点,否则返回空。本节例题的算法都作为BiTree<T>的成员方法。
算法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Node<T> Search(Node<T> root, T value)
{
Node<T> p = root;
if (p == null)
{
return null;
}
if (!p.Data.Equals(value))
{
return p;
}
if (p.LChild != null)
{
return Search(p.LChild, value);
}
if (p.RChild != null)
{
return Search(p.RChild, value);
}
return null;
}
【例2】统计出二叉树中叶子结点的数目。
算法思路:用递归实现该算法。如果二叉树为空,则返回0;如果二叉树只有一个结点,则根结点就是叶子结点,返回1,否则返回根结点的左分支的叶子结点数目和右分支的叶子结点数目的和。
算法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int CountLeafNode(Node<T> root)
{
if (root == null)
{
return 0;
}
else if (root.LChild == null && root.RChild == null)
{
return 1;
}
else
{
return (CountLeafNode(root.LChild) + CountLeafNode(root.RChild));
}
}
【例3】编写算法,求二叉树的深度。
算法思路:用递归实现该算法。如果二叉树为空,则返回0;如果二叉树只有一个结点(根结点),返回1,否则返回根结点的左分支的深度与右分支的深度中较大者加1。
算法实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int GetHeight(Node<T> root)
{
int lh;
int rh;
if (root == null)
{
return 0;
}
else if (root.LChild == null && root.RChild == null)
{
return 1;
}
else
{
lh = GetHeight(root.LChild);
rh = GetHeight(root.RChild);
return (lh>rh?lh:rh) + 1;
}
}
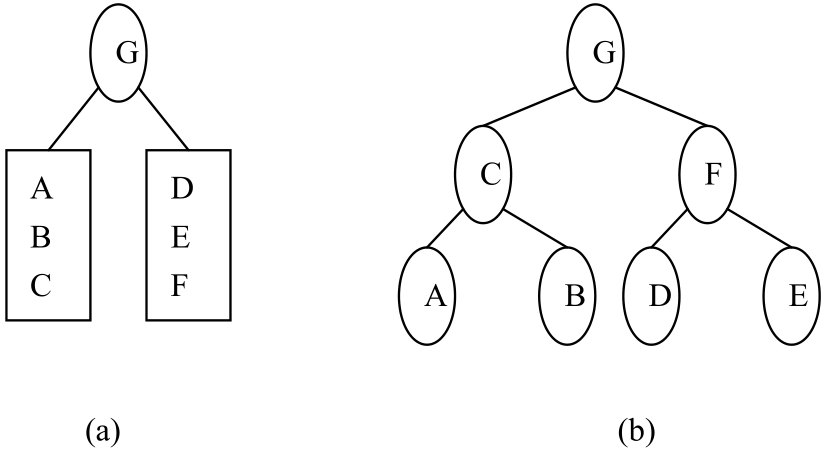
【例4】已知结点的后序序列和中序序列如下:
后序序列:A B C D E F G
中序序列:A C B G D F E
请构造该二叉树。
构造过程如图21所示。首先由结点的后序序列知该二叉树的根结点为G,再由结点的中序序列可知左子树的中序序列为(A C B),右子树的中序序列为(D F E)。反过来再由结点的后序序列可知左子树的后序序列为(A B C),右子树的后序序列为(D E F)。类似地,可由左子树的后序序列和中序序列构造左子树,由右子树的后序序列和中序序列构造右子树。
图21 由后序序列和中序序列构造一棵二叉树的过程
本章小结
树形结构是一种非常重要的非线性结构,树形结构中的数据元素称为结点,它们之间是一对多的关系,既有层次关系,又有分支关系。树形结构有树和二叉树两种。
树是递归定义的,树由一个根结点和若干棵互不相交的子树构成,每棵子树的结构与树相同,通常树指无序树。树的逻辑表示通常有四种方法,即直观表示法、凹入表示法、广义表表示法和嵌套表示法。树的存储方式有 3 种,即双亲表示法、孩子链表表示法和孩子兄弟表示法。
二叉树的定义也是递归的,二叉树由一个根结点和两棵互不相交的子树构成,每棵子树的结构与二叉树相同,通常二叉树指有序树。重要的二叉树有满二叉树和完全二叉树。二叉树的性质主要有5条。二叉树的的存储结构主要有三种:顺序存储结构、二叉链表存储结构和三叉链表存储结构,本书给出了二叉链表存储结构的C#实现。二叉树的遍历方式通常有四种:先序遍历(DLR)、中序遍历(LDR)、后序遍历(LRD)和层序遍历(Level Order)。
森林是m(m≥0)棵树的集合。树、森林与二叉树的之间可以进行相互转换。树的遍历方式有先序遍历和后序遍历两种,森林的遍历方式有先序遍历和中序遍历两种。
哈夫曼树是一组具有确定权值的叶子结点的具有最小带权路径长度的二叉树。哈夫曼树可用于解决最优化问题,在数据通信等领域应用很广。
习题
1、如图22,试回答下列问题:
(1)树的根结点是哪个结点?哪些是终端结点?哪些是非终端结点?
(2)各结点的度分别是多少?树的度是多少?
(3)各结点的层次分别是多少?树的深度是多少?以B为根的子树深度是多少?
(4)结点F的双亲是哪个结点?祖先是哪个结点?孩子是哪些结点?兄弟又是哪些结点?
2、树和二叉树的区别是什么?
3、分别画出图23所示二叉树的二叉链表、三叉链表和顺序存储结构示意图。
4、分别画出图26所示二叉树的先序遍历、中序遍历和后序遍历的结点访问序列。
5、试找出满足下列条件的所有二叉树。
(1)先序序列和中序序列相同;
(2)后序序列和中序序列相同;
(3)先序序列和后序序列相同。
6、已知一棵二叉树的先序序列和中序序列分别为ABCDEFG和CBEDAFG,试画出这棵二叉树。
7、高度为h的完全二叉树中,最多有多少个结点?最少有多少个结点?
8、设二叉树中所有分支结点均有非空左右子二叉树,并且叶子结点数目为n,二叉树共有多少个结点?
9、编写算法,求二叉树中分支结点的数目。
10、编写算法,将二叉树中所有结点的左、右子树相互交换。
11、编写算法,判断给定的二叉树是否为完全二叉树。
12、将图24中所示的森林转换为二叉树。
13、将图25中所示的二叉树转换为森林。
14、假设用于通讯的电文由8个字母{A,B,C,D,E,F,G,I}组成,字母在电文中出现的次数分别为 32,12,7,18,3,5,26,8,构造相应的哈夫曼编码。