思考并回答以下问题:
问题
1 | def _fetch_server_list(self): |
程序会先下载一个XML,解析XML,通过country聚合server,重点关注循环部分。
1 | <settings> |
函数式编程
函数式编程的思考方式是:关注数据,观察输入数据,思考输出数据然后寻找一个函数可以把输入转换成输出。比如我们输入是一个list,期望得到一个int,那么reduce是最合适的。这就是函数式编程业务逻辑是第二位的,数据才是第一位的。
开始重构
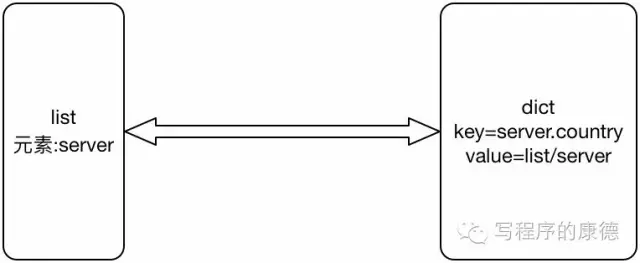
我们用一幅图表示,输入list()里面是server元素);输出dict(key是server.country,value是list,元素是server);处理过程其实就是分组。
下一步是寻找这样的函数,Python中有这样的一个函数,叫groupby,它接受两个参数,一个list,一个分组条件(函数,此处是server.attrib[“country”]);遗憾的是它只能对连续的数据分组所以我自己写了一个函数可以对非连续的数据分组。
1 | def groupby_discontinuous(iterable, func): |
defaultdict是一个特别的类,如果我们访问一个不存在的key,它会返回一个list(根据构造函数传递的值返回)。我们这样使用这个方法
1 | group_by_country = groupby_discontinuous(server_list, lambda server: server.attrib["country"]) |
lambda是一个匿名函数,参数是server,经过这个函数处理之后group_by_country就是按country分组的server list。(还没有添加上判断条件和server属性)
加上条件
在上面的函数映射过程中我们并不是所有数据都映射,有两个条件——country在白名单中(country_list),url可以被正则匹配到,还有一个细节——我们还需要用正则提取数据。下图是原始代码。
1 | if server.attrib["country"] in self.country_list: |
函数的输入是list,输出是list,处理过程是,过滤country并且url合法,同时提取url部分的server放到server.attrib[“server”]
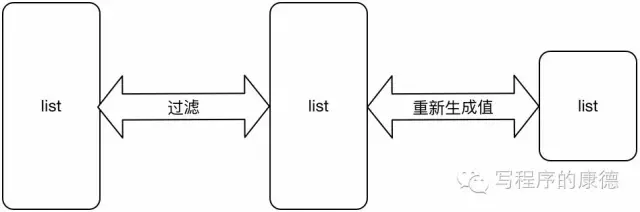
这样的函数肯定不存在,我们有两种办法:1. 自己实现一个,2. 利用现有的函数组装一个。函数式编程提倡实现原子函数,通过组合的方式使用。仔细分析一下这个函数其实包括两部分:
- 过滤,输入是list,输出是list,处理过程是判断country是否在country_list
- 重新生成,输入list,输出list,通过正则提取server放到server.attrib中,最后返回server(图中我用一个小的图表示左边的list元素数量比右边的多)
1 | pattern = r'http://([^/]+)/speedtest/upload\.php' |
过滤,我们可以通过filter这个函数实现。接受两个参数,一个是list,一个是过滤条件(函数)。我们的过滤函数包括两个条件,country in country_list,正则匹配成功。
重新生成,我们用map这个函数实现。接受两个参数,一个是list,一个是处理函数返回新值。
联合起来
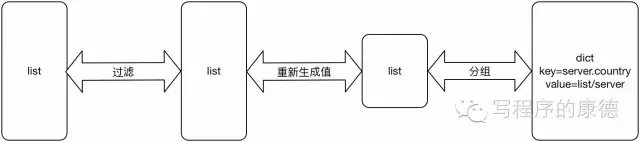
就是这个处理过程
总结
这是第一次尝试用函数式的思考方式来解决问题,这个过程多少有点不适应。总体而言在使用函数式的时候我们必须要熟悉常用的一些原子函数,通过思考输入、输出和处理方式来判断如何组装原子函数,是否需要新的函数。
当我们说函数式编程语言是first class functions的时候更多的是指用函数的方式思考问题而不是把函数当做数据类型处理,不可变、first class functions、高阶函数、惰性求值其实都是为了实现函数化,它们是手段而不是目的。
函数式编程语言不是一些奇技淫巧的语法糖,它是一种不同的编程方式,所以思考问题的方式也不再是思考业务逻辑,寻找对象;而是先思考数据再思考业务逻辑。